Optimizing C++
Discussion on Cholesky decomposition in C++
We used Windows Subsystem of Linux (WSL) to do the benchmarking. There are some differences with respect to pure Linux machines, which we outline where they exist. All code used in these examples is available at optimization_examples Github repo. For CUDA, we used the shipped NVIDIA examples, modified to use single precision floats for consistency.
Algorithm choice
There are two variants of Cholesky decomposition: LL^T and LDL^T. We use the LL^T variant here, except where outlined, to compare it to LDL^T variant.
We will review the following variants of the same algorithm
C++ with -O3 optimization
C++ with -O3 and -ffast-math optimization
C++ with BLAS (single threaded)
AVX
Eigen without MKL
MKL LAPACK (single threaded)
MKL LAPACK (multi-threaded)
CUDA
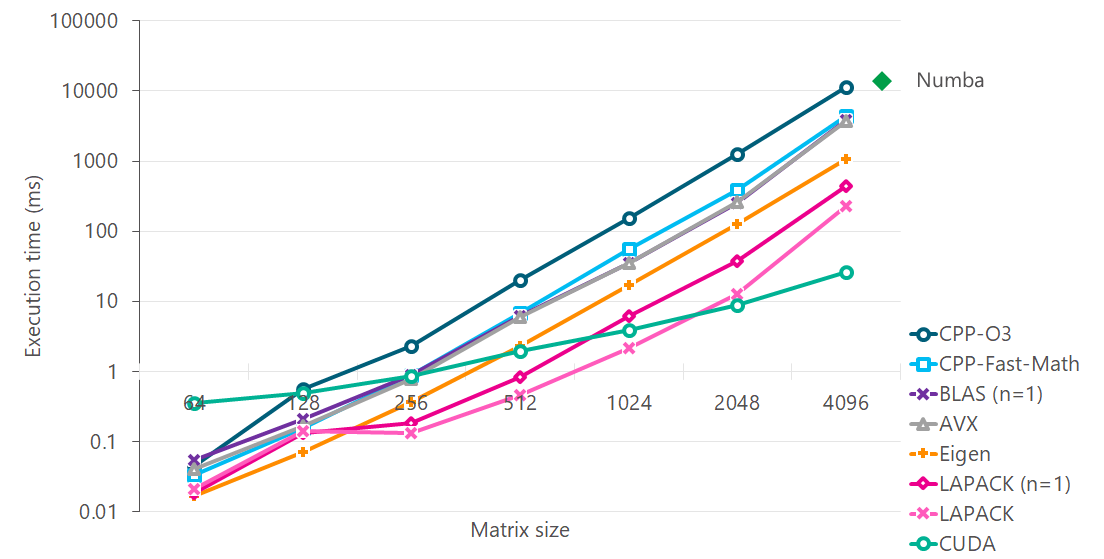
We use LAPACK, Eigen and CUDA implementations to set ourselves a target, rather than to evaluate them. The aim here is to see how far we can go from a pure C++ implementation to AVX one.
Conclusion
Without changing the basic Cholesky algorithm (i.e. using more efficient block-wise or recursive algorithms), SIMD instructions (AVX and higher) provide the best performance. After this point, speed gains can only be made using better algorithms. Similar perfomance may be achieved without writing SIMD intrinsics, by using
-ffast-mathinstead, but see Compiler options for a discussion of the cost involved in going down this route.Single threaded BLAS routines plugged in place of hand-written intrinsics show similar performance, suggesting that the handwritten intrinsics are optimal.
Eigen is great for small fixed-size matrices. Eigen (without MKL) has efficient linear algebra algorithms. Use them where you can.
LAPACK, as expected provide the best performance on CPU-only sytems. LAPACK achieves it’s performance from a combination of SIMD instructions, efficient data layout and efficient algorithms. LAPACK uses multiple threads if possible, and that can further boost performance. Similar speed gains can be made by using multiple threads for C++ or AVX code.
If you have access to a GPU, CUDA gives the best performance at large matrix sizes. A large fraction of the time is spent in data transfer, so it is worth chaining operations in order to minimize the trips to/from GPU.
Turbo Boost
Turbo Boost was disabled by following instructions here. With Turbo Boost enabled (which is the default), timings are not consistent because the CPU clock frequency changes (as per temperature of the machine). Anaconda uses Intel MKL and I have not tested this on an ARM processor. All timings were taken in Ubuntu 18.04 (Windows Subsystem for Linux). To verify that Turbo Boost is off, you may find it useful to download Intel extreme tuning utility and check that the Max Core Frequency stays roughly constant when running benchmarks.
numactl
Intel MKL uses as many threads as there are physical cores on a machine by default. This behaviour can be controlled by setting MKL_NUM_THREADS or OMP_NUM_THREADS, read by MKL in that order, or by tying down the process to specific cores on a machine. numactl allows you to do the latter. Use numactl -C 0 ./testCholesky to run the process on a single core, (only core 0 is accessible on WSL), and then use top to verify that this is happening. WSL apparently only uses a single core, but I did manage to see 200% CPU usage without any of the above measures (for a machine with 2 physical cores).
Compiler options
Compiler options can make quite a difference in the speed (as well as size and behaviour) of the code. -O2 is the highest level of optimization you can request without sacrificing safety of the code. Going from -O2 to -O3 shows very little gain in speed, but adding -ffast-math (which turns on -O3)does improve the speed noticeably. However, this comes at a cost.
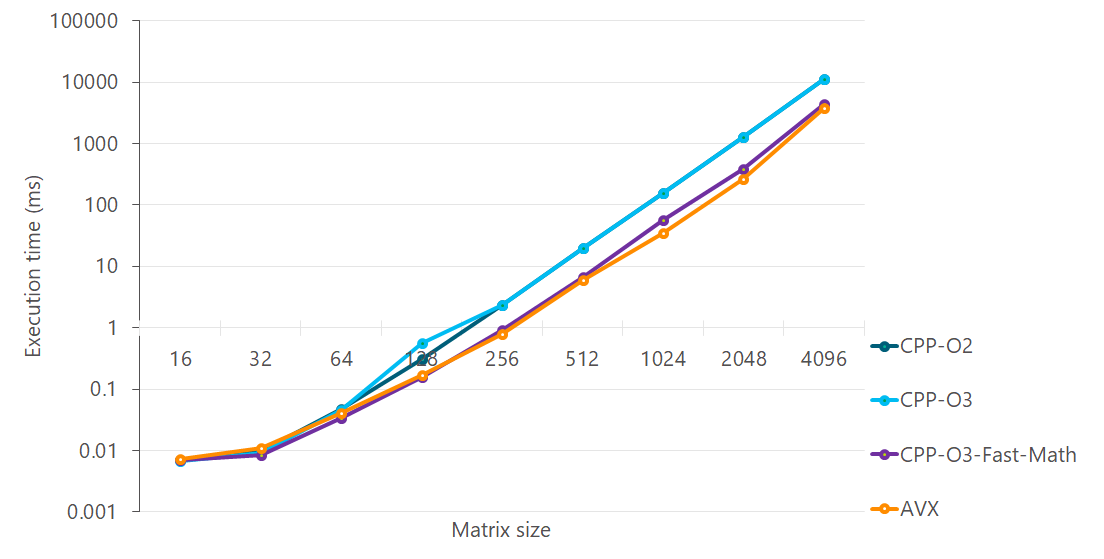
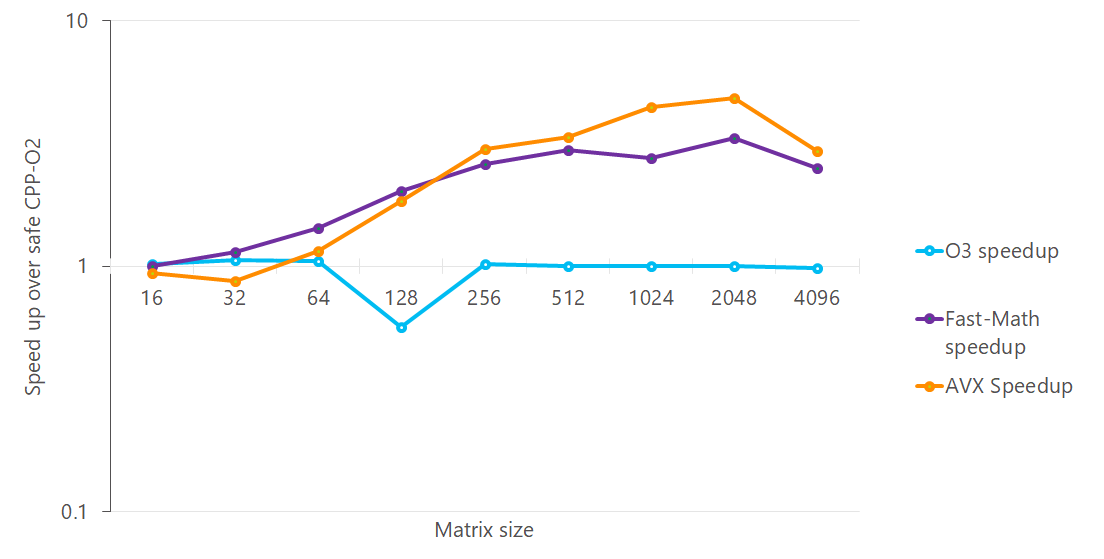
-ffast-math essentially turns on unsafe math optimizations and the changes due to this compiler option can propagate to the code that may link against your code in future (see Note of -ffast-math in References). While this option does make your code faster, it is very important that you understand the implications of turning it on and if possible, mitigate against it. A safer option that gives similar performance is to use either function-specific optimization (see Selective optimizations) or write some intrinsics or assembly to optimize just the bottlenecks rather than letting the compiler play wreak havoc on all of your code (and your downstream dependencies). We see from the graph below that AVX code performs better than the -ffast-math code and is also safer. This is definitely a case in which the effort of writing SIMD intrinsics is worth it.
If it was possible to use -ffast-math only at compile time and not at link time, then we could get the speedup for a single compilation unit (if we know that it is acceptable to turn on unsafe math optimizations for that part of the code) and not have any negative implications on any downstream dependencies. However, this is not currently possible with GCC (a bug report is under discussion) at the moment as CCFLAGS are automatically picked up by the linker when using GCC to link. Using ld to link circumvents this issue but that is hard.
Compiler version
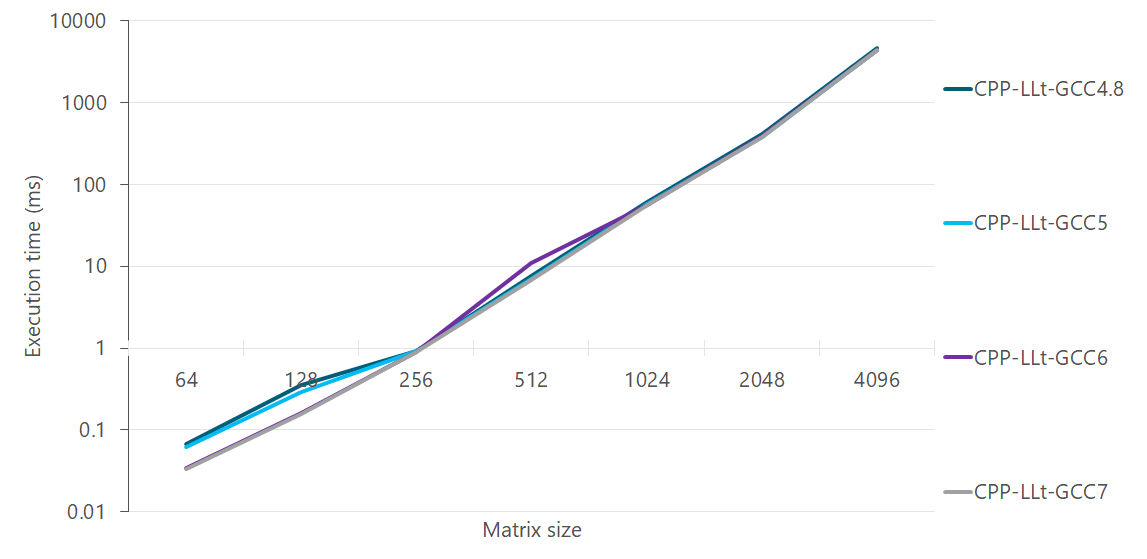
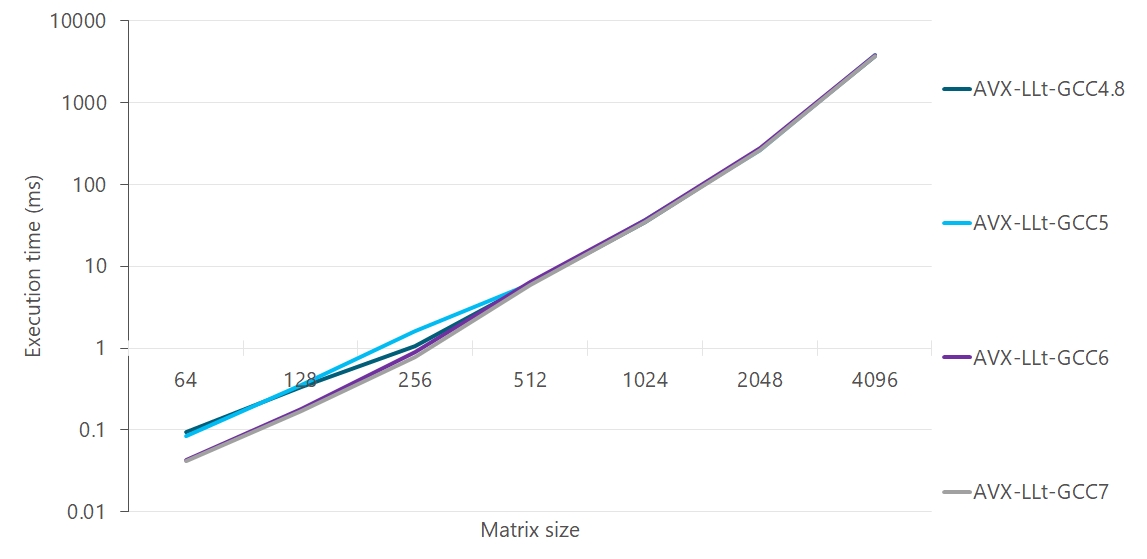
Off late, GCC has got a lot better at auto-vectorisation. Comparison of GCC versions 4.8, 5.5, 6.4 and 7.3 for C++ implementation:
Comparison of AVX implementations for same GCC versions:
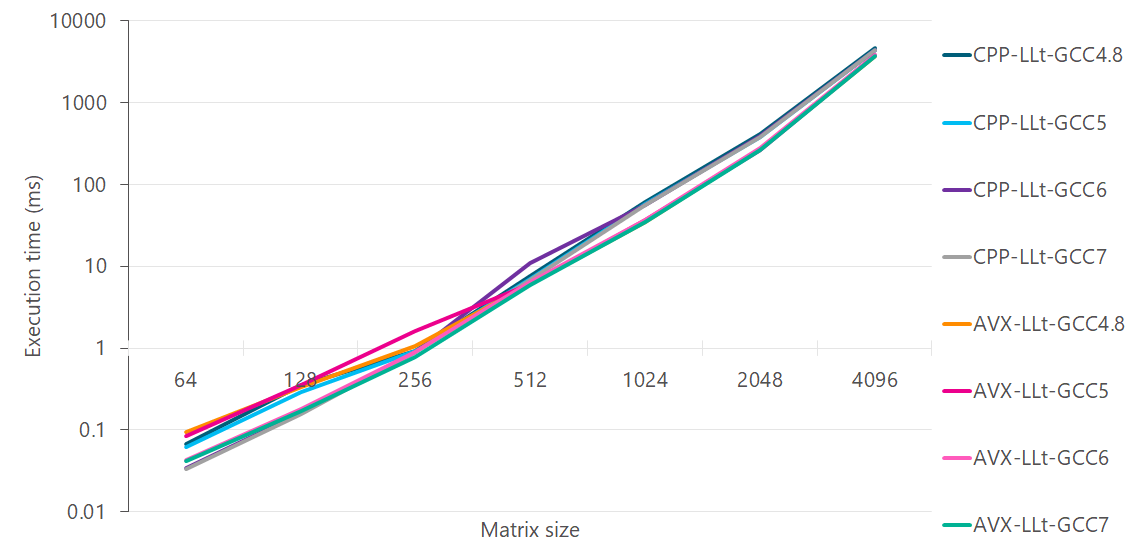
Putting it all together:
Takeaways:
Auto-vectorization has got better, and is especially noticeable at matrix sizes between 64-256.
C++ with auto-vectorization is closer to AVX from GCC 6 onwards. All C++ lines are with
-ffast-mathflag. Without it, the results are worse.
Best case limits for SIMD
Both Intel and ARM provide information on latency and throughput of each of their SIMD instructions. See for example, here, a screenshot of the Intel intrinsics guide.
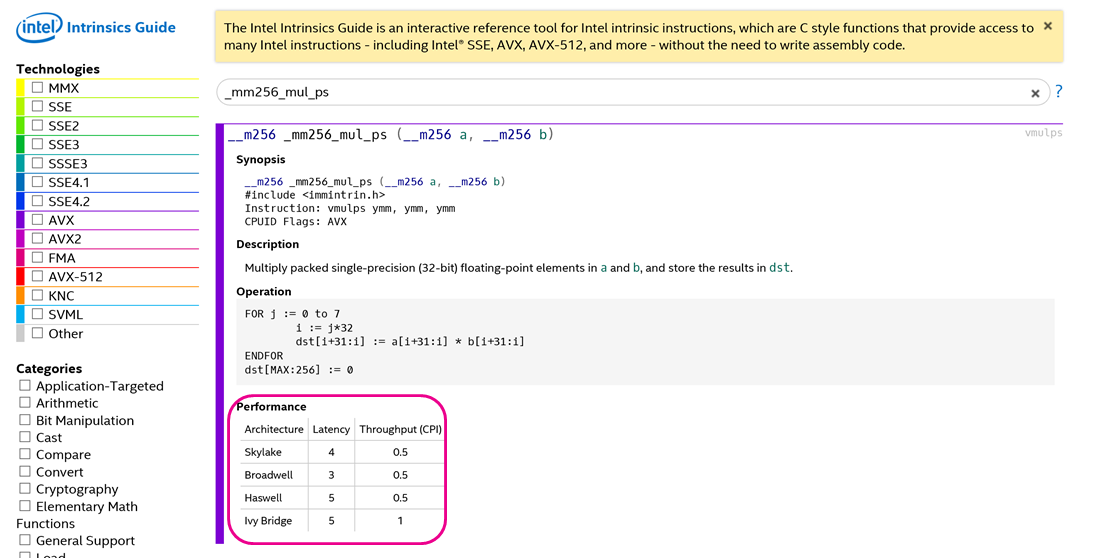
Looking these numbers up is a good way to choose between instructions and also determine whether or not it is worth coding up an intrinsics/assembly version of your code. For example, if the instruction you need is not available, and you have to use multiple instructions to get your work done, it may not actually speed up your code. You may have to redesign your algorithm.
Debugging auto generated assembly
Sometimes, you write intrinsics and you don’t get the expected speedup. In such cases, it could be that the compiler is not generating the assembly code you were hoping for. You can look at the disassembly and find out if this is the case. For example, this is the disassembly for add_avx function compiled with GCC 4.9 and GCC 5.4. GCC 5.4 unrolled the loop, whereas GCC 4.9 didn’t, hence the same code compiled with GCC 4.9 was slower.

Of course, it’s always best to upgrade to a newer compiler, if you have the freedom to do so. If you can’t change the compiler, then you may want to just write the assembly yourself (rather than use intrinsics), but if you have sufficient knowledge to write the assembly, you can get away by copying the assembly from the disassembly and then modifying it to use correct registers and so on. This would allow you to bypass the compiler asm doing the wrong conversion from intrinsics to assembly.
Handwritten intrinsics generally produce much more compact assembly code. Compiler’s auto-vectorized code contains a lot of no-ops and jumps. For example, the pairwise product AVX function in Cholesky example lead to 40 lines of assembly, whereas the C++ -O3 version lead to 220 lines of assembly. The more assembly there is, the harder it is to debug!
Selective optimizations
GCC provides a pragma to selectively optimize a function, i.e. change the compiler flags for a single function at a time. The compile string does not show the actual flags used as those are only printed on a per file basis when calling cmake or make. These flags are, therefore invisible, and hence a little dangerous, but the option is there, should you want to change compiler flags for selected functions. A better way of doing this may be to move code that needs to be optimized to a separate file and changing the compiler flags for just that file. That way the flags will be available for inspection (while allowing the benefit of optimization without polluting other compilation units).
#pragma GCC push_options
#pragma GCC optimize ("-ffast-math")
void functionToOptimize(const float * in, float * out)
{
...
}
#pragma GCC pop_options
WSL does not report the existance of AVX2 and a few other variants of Intel instruction sets via cat /proc/cpuinfo, so you would need to check the Intel processor specifications to determine whether a particular instruction set is available.